Available on IBM POWER
Andi Sama — CIO, Sinergi Wahana Gemilang
In most situations, when a trained machine learning-model is deployed, we can not explain how the model comes into certain conclusions in doing prediction — given data. We just “have to” accept what the model is telling us. This is the point in which H2O Driverless AI comes in play as XAI (explainable AI).
Illustration-1 shows H2O Driverless AI in action with 44% completion towards generating a model, it is doing training based on given parameters on a given dataset.

Artificial Intelligence, Machine Learning & Deep Learning — Today
Nowadays, when we have discussions about Artificial Intelligence (AI), the hottest trending topics have been on Deep Learning (DL), at least for the last 8+ years. DL is part of Machine Learning (ML), and ML itself is part of AI within the field of Computer Science.
As we dig even further — with Deep Learning, we have been building models mostly with Supervised Learning in which we generate models through approximation approach using chosen algorithm by learning directly from raw data, the labeled datasets (the datasets have number of input features with defined output target label). Once the model is generated, we can use the model to predict the output based on new input data through the process known as Inferencing (runtime).
In general, there are other two approaches in doing Machine Learning: Unsupervised Learning (learn from datasets without defined output label) and Reinforcement Learning (given a starting point and a target output, learn by executing actions that maximize the rewards to reach the output).
AI Data Pipeline


Illustration-2 (in brief) and illustration-3 (expanded view) show a typical AI Data Pipeline consisting of three major steps: Data Preparation, Modeling/Training and Deployment/Inferencing.
1. Data Preparation
Dataset may not be suitable to be directly used for training. Images, texts, sounds or videos for examples needs to be converted to numbers (integer or floating point) somehow before being processed by machine learning/deep learning algorithms, which is basically an optimization algorithm through approximation with math & statistics. In general, data needs to be carefully selected, cleansed or transformed before going to the algorithms.
According to an article in Harvard Business Review (Thomas C. Redman, 2018), collecting and preparing data for machine learning takes about six month on average.
2. Modeling/Training
Once data is ready, training can be started. Prior to the training we need to set a few hyperparameters such as epoch (number of iterations), learning rate (how fast the changes in small steps towards achieving global minima when doing stochastic gradient descent algorithm through 1st order derivative process (differentiation) on certain defined loss function) and dataset split ratio (dataset is typically divided into several portions such as [70%:15%:15%] or [60%:20%:20%] for the purpose of [Training:Validation:Testing].
We need to specify hyperparameters named k for example (number of expected clusters to group our dataset) if we select k-nn algorithm for Unsupervised Learning.
For Supervised Learning, in which we have a set of input data associated with a set of output label, the number of training data is typically in the order of thousands per class (or per type of object in which we want to find the relationship between a set of input data and a set of labeled output).
We need to review the result through some metrics (depends on chosen algorithm) such as accuracy, confusion matrix, mAP (mean Average Precision) and IoU (Intersection over Union) to find the best performing model. The selected model can then be deployed.
3. Deployment (Inferencing)
This is the step in which we use the trained model to predict the outcome, given new data. Deployment can be done on-premise or in the cloud, using either CPU or GPU with a few different approaches depending on different purposes: accessed by mobile application or web application or even accessed by a sub-process within an application.
The challenge in inferencing is when a trained model is deployed and given new data. The model is just like a blackbox as we can not explain why the model is giving certain output, given input. It’s just by the process of neural network training, the model has a set of optimized hyper-parameters (thousands/millions or even billions of optimized values) that it can come up with certain conclusions with certain confidence levels (nowadays, mostly above 90%) built through a series of mathematical & statistical processes.
This is the point in which H2O Driverless AI comes into play, trying to approach the problem of unexplainable AI-model and make it explainable. The term in industry known as eXplainable AI (XAI).
H2O Driverless AI as Explainable AI (XAI)
For some of us that are familiar with H2O.ai machine learning framework, H2O Driverless AI is totally different, although it comes from the same provider. H2O.ai framework is the open-source version (H2O.ai, 2020c) while H2O Driverless AI is the closed-source version, meaning the use of H2O Driverless AI is chargeable.
H2O.ai is like Google tensorflow or Facebook pytorch open source machine learning packages for example. While H2O Driverless AI is like IBM PowerAI Vision (IBM PAIV, a software that is similar to H2O Driverless AI focusing on Vision). Take IBM PAIV for instance, the software can utilize underlying machine learning frameworks based on tensorflow, keras, caffe or pytorch for instance, that are packaged in open-source version of IBM Watson Machine Learning Accelerator (WMLA) called IBM Watson Machine Learning Community Edition (WML-CE).
As stated in H2O Driverless AI online documentation (H2O.ai, 2020b) “H2O Driverless AI empowers data scientists to work on projects faster and more efficiently by using automation to accomplish key machine learning tasks in just minutes or hours, not months. By delivering automatic feature engineering, model validation, model tuning, model selection and deployment, machine learning interpretability, bring your own recipe, time-series and automatic pipeline generation for model scoring, H2O Driverless AI provides companies with an extensible customizable data science platform that addresses the needs of a variety of use cases for every enterprise in every industry.”
Take feature engineering for example — without tools, a data scientist may need to tune multiple parameters and spend long days or even weeks to find the best features that can generate the best results by exploring & testing multiple algorithms — such as PCA (Principle Component Analysis) or T-SNE (t-Distributed Stochastic Neighbor Embedding) for dimensionality reduction of given features (input dataset).
Machine Learning Interpretability (MLI) is another strong capability. The online documentation stated (H2O.ai, 2020b) “H2O Driverless AI provides robust interpretability of machine learning models to explain modeling results with the MLI capability. MLI enables a data scientist to employ different techniques and methodologies for interpreting and explaining the results of its models with four charts that are generated automatically including: K-LIME, Shapley, Variable Importance, Decision Tree, Partial Dependence and more.”
The capability to bring our own recipes (custom codes) enables the creation of custom transformers (data transformation: kind of doing ETL — extract, transform & load in datawarehouse), models (algorithms to do training) and scores (i.e. targeted for classification or regression).
All of that, are provided automatically in an intuitive User Interface in H2O Driverless AI.
Model Training with H2O Driverless AI
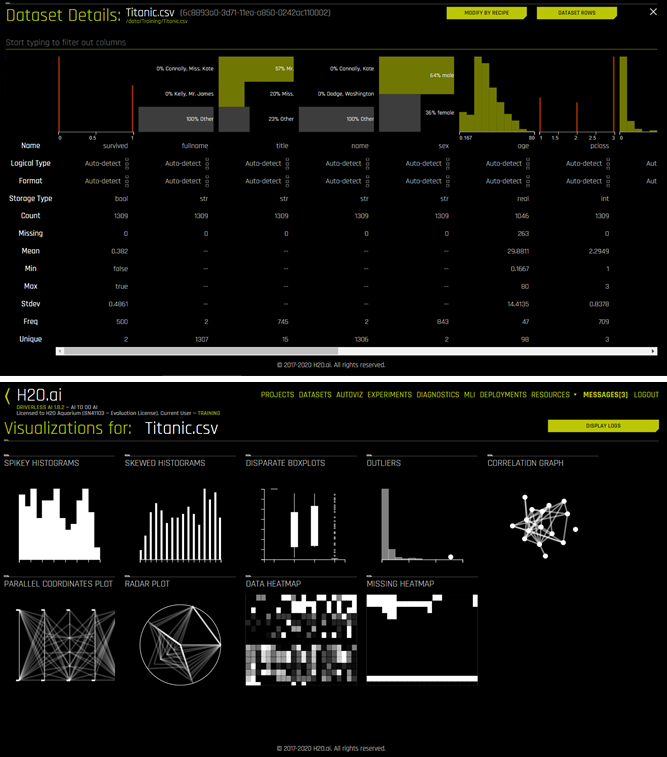
Let’s start by logging in to installed trial version of H2O Driverless AI, provided by H2O.ai on cloud for anyone to experience. At first, we will be presented with the welcome screen, then we can browse through the sample datasets (illustration-4). In this case, we select titanic dataset for training (titanic_train.csv, comma separated values) and dataset for testing (titanic_test.csv), then visualize its properties and key statistics (illustration-5).
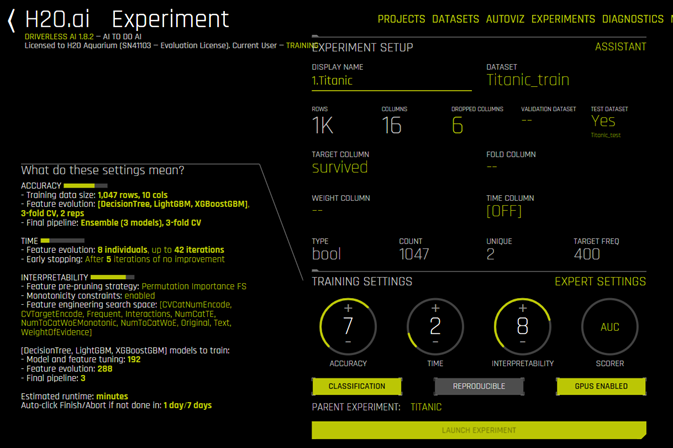
Once the data is loaded (both for training & test), we can start doing training to generate model after adjusting a few parameters. In H2O Driverless AI for supervised learning (and this is our case with the titanic dataset), the simplest one is to define the target column (label), and input features in our dataset, then selecting the 3 available knobs to determine level of accuracy, time as well as interpretability.
Accuracy determines the number of folds (cross-validation) in splitting training dataset as well as selection of algorithms.
Time determines number of iterations/epochs that are related to number of concurrent GPUs that we have, early stopping at certain iteration if the result is not improving.
Interpretability shows how each feature directly impacts each individual row’s prediction, automatically builds linear model approximations to regions of complex H2O Driverless AI models’ learned response functions, shows how the logic of the model is applied to any given individual, shows the average H2O Driverless AI model prediction and Its standard deviation for different values of important original features, escribes how the combination of the learned model rules or parameters and an individual row’s attributes affect a model’s prediction for that row while taking nonlinearity and interactions into effect, as well as test for sociological biases in models.
Typically we do not set all knobs to its maximum values, we need to balance the computing resources that we have (CPUs, GPUs, Memory) for expected accuracy, time to train and interpretability. The most accurate model with best performance (minimum interpretability) can be generated for example by setting accuracy, time to maximum & interpretability to minimum to be 10, 10, and 1. In this case where we have limited GPUs and would like to train in quite fast with good accuracy, we set accuracy, time & interpretability to 7, 2 and 8 consecutively (illustration-6).
We can always inspect what all the settings mean by placing the mouse over the terms that we want to know. Illustration-6 shows the descriptions of accuracy, time & interpretability related to loaded dataset.
Expert Settings
If we have been using H2O Driverless AI for sometime, and would like to explore more on finer detail settings in addition to just standard setting like the 3 provided knobs, we can always go to “Expert Settings” (illustration-7), before deciding to add our custom recipe (either for doing transformation, modeling or scoring) for example.
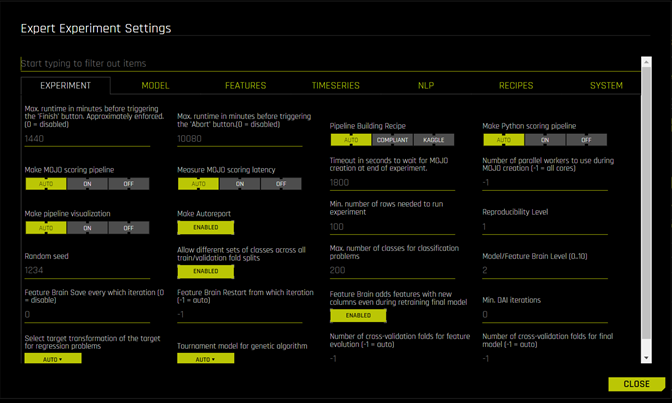
Loading custom recipes from external system (thru URL) or upload custom recipes from our local system for example, are ones of those things that can be done in Expert Settings. Max Runtime in Minutes Before Triggering the Abort Button is also a setting that Data Scientists want to tweak before starting the training.
Random Seed may also important to set for the experiment — when a seed is defined and the reproducible button is enabled, the algorithm will behave deterministically. If reproducibility is deemed important across multiple systems, we can set Reproducibility Level to its maximum level which is 4. By default this setting is 1: Same experiment results for same O/S, same CPU(s), and same GPU(s), while if it is set to 4, it means that ‘Same experiment results for same O/S (best approximation)’.
There are a lot of more Expert Settings to choose from that we can play around according to our needs to influence how the training is done. In most of the cases, adjusting just the 3 knobs will be enough.
Launch The Training
Once we are satisfied with all the settings, we can just press the “launch experiment” button to start the training process (illustration 8 shows the training in progress). Just sit tight and watch how H2O Driverless AI do all the processes from selecting competing algorithms (illustration 8 shows LightGBM with current AUC score = 0.8761 shown within “Iteration Data — Validation” window at 55% training completion). The score will keep improving as the training progresses.
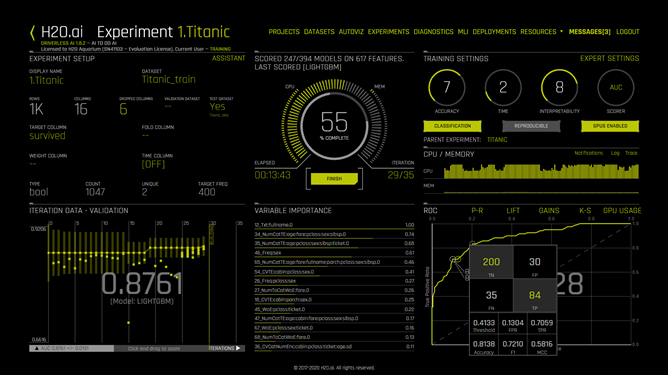
Note that AUC (Area Under Curve) is the scorer we selected before launching the experiment (see: illustration 6), while LightGBM is a gradient boosting framework developed by Microsoft that uses tree based learning algorithms.
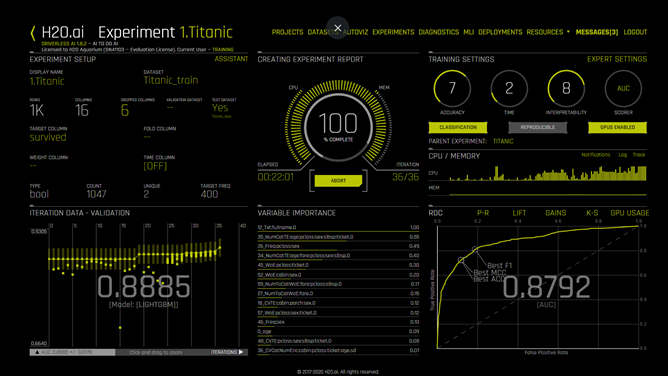
As the training is progressing and eventually completed (in 22 minutes and 1 second) within just 36 iterations (illustration 9), the final AUC score is produced. In this case, we get final AUC score = 0.885, still with LightGBM. Pay attention also to Variable Importance chart that shows the significance of original and newly engineered features.
Wrapping Up
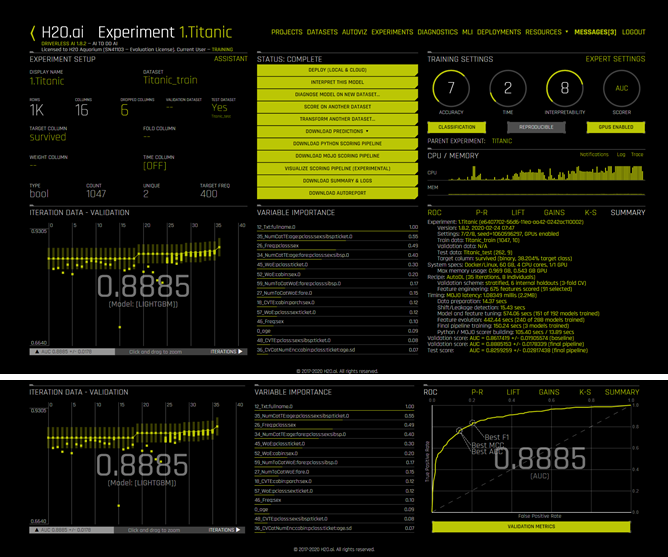
A summary of our experiment (meaning, a model has been generated from the experiment) is shown in illustration-12. Ones to inspect are validation score and test score with generic guideline that if both tend towards similar values, it is the indication that our generated model is just right and not suffering from either underfitting or overfitting.
Underfitting occurs when “a statistical model cannot adequately capture the underlying structure of the data”. Overfitting (in statistics) is “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably” (Wikipedia, 2020). Cross Validation technique that is applied in our case for example, is used to calculate mean response to prevent overfitting.
Automatic model documentation is provided through an Autoreport (Autodoc). This Autodoc is generated for each experiment and includes details about the data used, the validation schema selected, model and feature tuning, and the final model created. Autodoc document can be downloaded for further offline review (illustration-10).
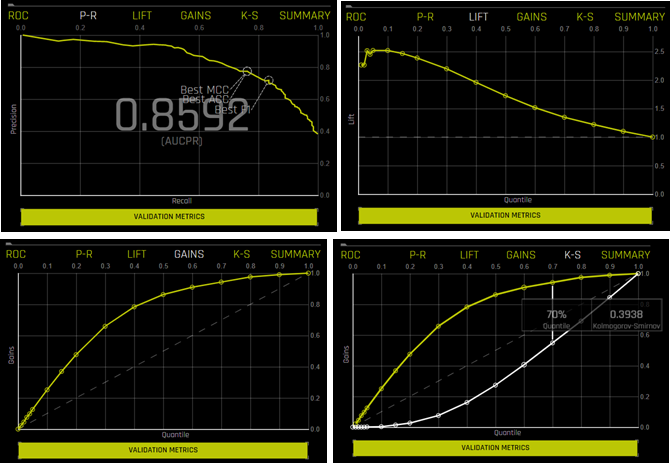
Model Deployment & Inference
Following the completion of the training, we can deploy the generated model either locally in our current system: localhost (REST-enabled server) or to cloud.
By deploying to Amazon Web Services (AWS) Lambda (Serverless, as FaaS — Function as a Service) for example, we will get our own generated API key and URL to access which can be integrated in our own external application. A similar approach is valid for deploying in any FaaS provided cloud such as IBM Cloud, Google Cloud Platform (GCP) or others.
Machine Learning Interpretability — MLI
H2O Driverless AI provides an exciting feature called Machine Learning Interpretability, shortened as MLI to explain model results in human readable format rather than complex neural network architecture with a bunch of optimized parameters consisting millions or even billions of 16, 32 or 64-bits floating point numbers, the typical content of a trained-model. Note that, certain optimized models targeted for edge deployment will have much reduced size as well as converted floating points to integers.
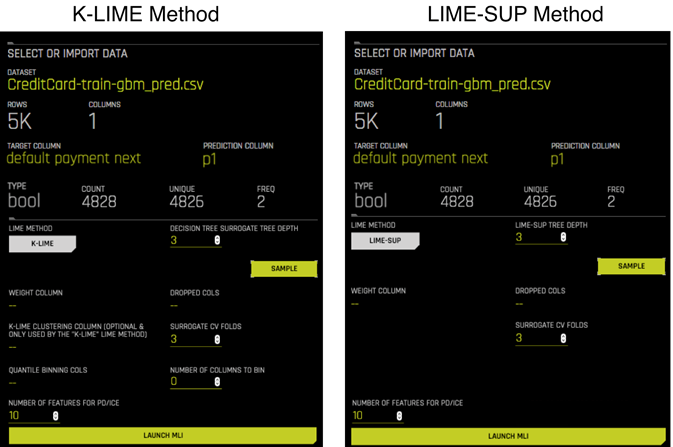
The H2O Driverless AI online documentation stated (H2O.ai, 2020b) “A number of charts are generated automatically (depending on experiment type), including K-LIME, Shapley, Variable Importance, Decision Tree Surrogate, Partial Dependence, Individual Conditional Expectation, Sensitivity Analysis, NLP Tokens, NLP LOCO, and more. Additionally, you can download a CSV of LIME and Shapley reasons codes from this view.”
Further, according to the documentation, MLI is currently supported for regular (non-time-series) experiments: binary classification, regression, multiclass classification; as well as time-series experiments. Current limitations include no support for multiclass time series experiments (including models that were created up to version 1.7.0).

Illustration-13 and illustration-14 show an H2O Driverless AI’s MLI page for a different model adapted from H2O Driverless AI online documentation (it’s a different model than the one we are discussing: titanic dataset). This model has been trained based on credit card dataset. The target label is next month payment, and the model is trained to predict whether the next month payment will be default or not.
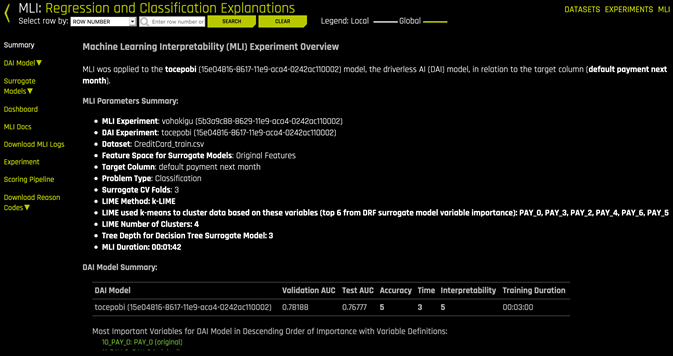
According to H2O Driverless AI online documentation “This model interpretation page provides an overview of the interpretation, including the dataset and Driverless AI experiment (if available) that were used for the interpretation along with the feature space (original or transformed), target column, problem type, and k-Lime information. If the interpretation was created from a Driverless AI model, then a table with the Driverless AI model summary is also included along with the top variables for the model.”
H2O Driverless AI on IBM POWER
As stated in H2O Driverless AI online documentation “H2O Driverless AI is optimized to work with the latest Nvidia GPUs, IBM Power 9 and Intel x86 CPUs and to take advantage of GPU acceleration to achieve up to 30X speedups for automatic machine learning. Driverless AI includes support for GPU accelerated algorithms like XGBoost, TensorFlow, LightGBM GLM, and more.”
H2O Driverless AI has been tested locally here at Sinergi Wahana Gemilang in Jakarta, Indonesia. It runs smoothly on local rack type 2U-machine: IBM POWER AC922 (Accelerated Computing, optimized for AI Training) with 20 POWER9 CPU cores, 2 NVidia Tesla V100 GPUs and 128GB System RAM.
If we do not have access to such a powerful GPU-powered machine locally, we can also experience H2O Driverless AI on IBM provided systems (IBM, 2020) available in IBM Systems Cloud (IBM Systems Worldwide Client Experience Centers Cloud, CECC). IBM CECCs are located around the world such as USA, Germany, France, China and Mexico. The Centers provide world class offerings that leverage technical subject matter expertise and provide access to the leading edge systems infrastructure that enable insights and innovation.
One configuration that we can reserve for 14 days (can be extended for certain approved use cases) consists of 1 instance of IBM POWER9 KVM configured with 32 vCPUs, 64GB RAM, 200 GB Disk, and 1 NVIDIA Tesla V100 with PCI GPU. Other available configuration in IBM CECC includes IBM POWER8 KVM with 32 vCPUs, 64GB RAM, 200GB Disk, 1 NVIDIA Tesla P100 with PCI GPU.
What’s Next?
The developments of emerging technology in the area of Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) have been significantly advancing in the past 8+ years, especially due to advancements in hardware: GPUs, and the inventions of new deep learning algorithms & neural network architectures as well as the availability of large amount of dataset (Bigdata).
The more mature approach in doing deep learning at this moment is still through Supervised Learning. It means that, in order for the model to do prediction, it needs to be trained with a lot of data (ideally thousands or millions of data). In supervised learning, we need to label the data before the model can generate the pattern (in the form of: model) to predict new untrained data. H2O Driverless AI, which is also distributed by IBM in Indonesia falls in this category of Supervised Learning mostly in Non-Vision for processing texts and numbers (classification or regression). It can also train type of dataset for doing Natural Language Processing (NLP).
For us in Indonesia, the opportunities have been opening since the last few years while the numbers and capabilities of the implementers in the area of AI are still limited. This is a great opportunity for the players in Information Technology industry to quickly grab the market by starting with the ready implementable solution such as H2O Driverless AI, that can utilize the power of hardware platform such as IBM AC922 with its highspeed NVlink connectivity both between CPUs-GPUs, as well as between GPUs-GPUs.
The good way to start (technically) is just to experience the product by ourselves. H2O Driverless AI trial-edition is available on cloud for 2-hours for anyone to experiment the true power of automated and explainable AI.
Well, what’s are we waiting for?. Let’s get started by doing something. The good time is now.
References
Andi Sama et al., 2019, “Think like a Data Scientist”.
Andi Sama, 2019a “Image Classification & Object Detection on IBM PowerAI Vision”.
Andi Sama, 2019b, “AI-Model Inferencing”.
H2O.ai, 2020a, “Driverless AI Training (1.8.4.1)”.
H2O.ai, 2020b, “H2O Driverless AI online documentation”, v1.8.4.1.
H2O.ai, 2020c, “H2O AI”.
IBM, 2020, “IBM Systems Worldwide Client Experience Centers Cloud (CECC)”.
IBM Indonesia, 2020, “H2O Driverless AI: Data Science Simplified”.
Thomas C. Redman, 2018, “If Your Data Is Bad, Your Machine Learning Tools Are Useless”, Harvard Business Review, April 2018 Edition.
Wikipedia, 2020, “Overfitting” .